Las tendencias recientes en LLMs para 2025
Primer capítulo sobre las tendencias recientes en LLMs para 2025, en el cual se expone el Contexto General sobre los Modelos de Lenguaje Grande (LLMs).
5/13/20254 min leer

Capítulo 1: Introducción y Contexto General sobre los Modelos de Lenguaje Grande (LLMs)
A partir de hoy, vamos a desarrollar una serie de artículos como parte de un informe exhaustivo sobre las tendencias más recientes en el campo de los Modelos de Lenguaje Grande (LLMs) hasta 2025, estructuraremos el contenido en diferentes secciones que aborden los aspectos clave: evolución tecnológica, los modelos emergentes más relevantes, las técnicas innovadoras en entrenamiento y optimización, así como las principales aplicaciones prácticas que están revolucionando sectores diversos.
1.1 Definición y Concepto Fundamental de los LLMs
Los Modelos de Lenguaje Grande, comúnmente conocidos por sus siglas en inglés LLMs (Large Language Models), representan una categoría avanzada de sistemas de inteligencia artificial cuya función principal es el procesamiento, comprensión y generación del lenguaje natural humano. Básicamente, un LLM es un tipo de modelo de machine learning que utiliza redes neuronales profundas y extensos conjuntos de datos para aprender patrones, relaciones semánticas y sintácticas en el idioma escrito o hablado. Con tal entrenamiento, estos modelos pueden predecir, completar, traducir y crear texto plausible que imita la producción lingüística humana.
Una definición sintética que resume su naturaleza es la siguiente: "Un modelo de lenguaje grande es un algoritmo de inteligencia artificial que emplea técnicas de aprendizaje profundo y conjuntos de datos masivos para entender, interpretar, y generar lenguaje humano."(TechTarget) Esta capacidad está basada en arquitecturas de deep learning de alta escala que suelen contar con millones o miles de millones de parámetros, permitiendo así un modelado preciso de la complejidad inherente al uso natural del lenguaje.
1.2 Evolución Histórica y Avance Tecnológico
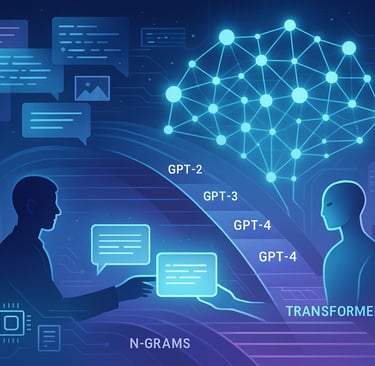
El origen de los LLMs se remonta a la evolución de los modelos estadísticos y los enfoques de aprendizaje automático para el procesamiento de lenguaje natural (PLN), empezando con modelos basados en n-gramas y luego con modelos neuronales recurrentes (RNNs). Sin embargo, el salto disruptivo llegó con la introducción de arquitecturas Transformer en 2017, que optimizaron la paralelización del entrenamiento y aumentaron la capacidad para capturar contextos extensos en texto.
Desde entonces, los LLMs han evolucionado rápidamente, destacándose en hitos como GPT-2, GPT-3, y GPT-4, entre otros. Cada iteración ha incrementado dramáticamente el número de parámetros y la calidad de salida, además de incorporar nuevas funcionalidades como capacidades multimodales (texto, imagen, audio combinados). Este desarrollo ha permitido que modelos como GPT-4o y otras variantes recientes no solo respondan preguntas sino que también generen contenido creativo, código de programación, y ejecuten tareas complejas de razonamiento.
1.3 Importancia y Alcance Global
El impacto de los LLMs trasciende el ámbito puramente académico para convertirse en una de las tecnologías fundamentales que están revolucionando múltiples sectores industriales y sociales. Empresas de tecnología, finanzas, salud, educación, y gobierno están adoptando estas herramientas para mejorar la interacción con usuarios, automatizar procesos, y potenciar la toma de decisiones mediante análisis de lenguaje avanzado.
Del mismo modo, se estima que el mercado global de soluciones basadas en modelos de lenguaje grande experimenta un crecimiento exponencial, impulsado por la demanda de automatización inteligente, asistentes virtuales, generación de contenido, y análisis de datos textuales. Este crecimiento económico y tecnológico refuerza la importancia estratégica de entender tanto las capacidades como las limitaciones de los LLMs, así como sus implicaciones éticas y de seguridad.
1.4 Funcionamiento Básico: ¿Cómo Trabajan los LLMs?
Un LLM se entrena en grandes conjuntos de texto que pueden incluir libros, artículos, conversaciones, código, datos científicos, y más. Durante el entrenamiento, el modelo aprende a predecir la siguiente palabra en una secuencia dada una historia previa — lo que se denomina modelado del lenguaje autoregresivo — o a completar otras tareas lingüísticas mediante aprendizaje supervisado. Este aprendizaje se basa en ajustar los parámetros internos del modelo para minimizar el error en las predicciones.
Además, en su funcionamiento operativo, los LLMs emplean diferentes técnicas avanzadas de prompting, como few-shot learning (aprender con pocos ejemplos) y zero-shot learning (ejecutar tareas sin ejemplos específicos), que les permiten adaptarse a múltiples dominios y requerimientos sin necesidad de reentrenamiento completo. También es frecuente la integración de capacidades de razonamiento avanzado (Chain-of-Thought o Tree-of-Thought) para resolver problemas complejos más allá de la simple generación textual.
1.5 Perspectivas Iniciales para los Capítulos Posteriores
Este capítulo introductorio sienta la base para examinar en profundidad las tendencias actuales y futuras de la tecnología LLM en términos de:
Los últimos modelos y sus innovaciones técnicas para 2025.
Nuevas técnicas de entrenamiento, optimización y uso eficiente de recursos.
Integración con fuentes externas para verificación de hechos y datos en tiempo real.
La variedad creciente de aplicaciones que abarcan desde chatbots hasta generación de código y traducción automática.
Los riesgos, desafíos éticos y de seguridad, así como las métricas de control y evaluación.
Las perspectivas y tendencias que definirán el rumbo de los LLMs en los próximos años.
Estos temas se desarrollarán con respaldo de datos recientes y artículos especializados recogidos hasta mayo de 2025.
Finalmente es importante indicar que en el último capítulo (7) se estará incluyendo el listado de las fuentes de información consultadas.